「ある文字列に日本語が含まれるか」をJavaScriptの正規表現で判定してみよう
こんにちは。フロントエンドエンジニアの辻です。
今回は、表題通り「ある文字列に日本語が含まれるか」をJavaScriptの正規表現で判定するコードを書いていきます。
Gaji-Laboは様々なスタートアップを支援しています。
あるプロダクトのバックエンド(Node.js)で「とあるデータの特定のプロパティに日本語が含まれるか判定するには、どうすれば良いのか」を調査する機会があり、そこでJavaScriptの面白い機能を見つけることができました。
「ある文字列に日本語が含まれるか」を判定するコード
先にお断りしておきますが、次のコードはあくまで『ぼくのかんがえたさいきょうの「ある文字列に日本語が含まれるか」を判定するコード』です。
万事を解決するコードではありません。(理由は後述します。)
この点のみご注意ください。
/**
* 引数に日本語が含まれるかを判定する
*
* @param {string} target
* @return {boolean}
*/
const hasJapanese = (target) => {
// ひらがな
if (/\p{Script=Hiragana}/u.test(target)) return true;
// カタカナ
if (/\p{Script=Katakana}/u.test(target)) return true;
// 漢字
if (/\p{Script=Han}/u.test(target)) return true;
// 約物・記号など
if (/\p{Script=Common}/u.test(target)) return true;
return false;
};hasJapanese関数のインターフェースはシンプルです。
引数に文字列をとり、返り値として「引数に日本語が含まれているか」の真偽値を返します。
それでは、さっそく実行してみましょう。

うまく「日本語が含まれているか」を判定できていますね!!
ひらがな・カタカナはもちろんのこと、約物・記号にもうまく対応できています。
漢字もいい感じです。漢字だけに。
ソースコードの解説
\pとScriptとuを使った正規表現
それでは、hasJapanese関数の処理を見ていきましょう。
まずはじめに/\p{Script=Hiragana}/uなる不思議な正規表現が目に止まりますね。
JavaScriptの正規表現では、\pでUnicodeプロパティを指定したマッチが可能になります。
Unicodeプロパティとは、Unicodeの符号とは別に文字に付与された様々な情報を指します。
例として、ひらがなの「あ」のプロパティを見てみましょう。
> 「あ」のプロパティ
符号のU+3042の他に、実にたくさんの情報が「あ」に付与されているのが分かります。
さて、よく探してみると「あ」のプロパティの中に「Script Hiragana」とありました。

Scriptとは文字体系のことで、”同種の表記に使われるひとまとまりの文字の体系”を意味します。
(Wikipediaより引用。詳しくは文字体系と表記体系 | Wikipediaをご覧ください。)
察しの良い読者はもう気づいたかと思いますが、/\p{Script=Hiragana}/uとは「\pでUnicodeプロパティを検索対象とし、そのうちのScript(文字体系)がHiraganaに該当する文字にマッチさせる」正規表現となります。
(ちなみに、本記事執筆時点でScriptの他に指定可能なUnicodeプロパティとして、General_Category(gc)とScript_Extensions(scx)があります。詳しくは、Unicode 文字クラスエスケープ: \p{…}, \P{…} property | mdnと、Table 69: Non-binary Unicode property aliases and their canonical property namesをご覧ください。)
最後のuは正規表現でサロゲートペアを扱うために付与します。
本題から反れるため、サラッとした解説になりますが、「サロゲートペア」とは、もともと2バイトだったUnicodeの符号を4バイトに拡張する仕組みのことです。
例えば、漢字の「魚へんに花(ほっけの事です。システムの都合上、この表記になっています。)」の符号はU+29E3D(= 10 | 10011110 | 00111101)で2バイトより大きいです。
2バイトよりも大きい符号が使われているにも関わらず、Unicodeが文字集合として成り立つのは、サロゲートペアのおかげです。
> 「魚へんに花(ほっけ)」のプロパティ
mdnの解説ページでは、絵文字を使ってuのあるなしの違いを説明していますね。
/\p{Script=XXX}/uは、現代の各種ブラウザ・Node.js・Denoでサポートされているため、フロントエンドでもバックエンドでも気兼ねなく利用できます。
> Unicode 文字クラスエスケープ: \p{…}, \P{…} ブラウザーの互換性| mdn
> escape: \p{…}, \P{…} | Can I use
もちろん、ひらがな・カタカナ・漢字に限らず、他の文字体系もマッチさせられます。
mdnの解説ページでは、/\p{Script=Latin}/uでラテン文字に。/\p{Script=Grek}/uでギリシャ文字に。/\p{sc=Cyrillic}/uでキリル文字にマッチさせるサンプルが掲載されていますね。
/\p{Script=XXX}/uでマッチする範囲を確かめる方法
/\p{Script=XXX}/uでマッチする範囲はUnicode Utilities: UnicodeSetで確認できます。
試しにUnicode Utilities: UnicodeSetの「Input」欄に「\p{Script=Hiragana}」と入力してみると、そのマッチする範囲がページ下部に展開されます。
(「/\p{Script=Hiragana}/u」と入力すると「/」と「u」が含まれてしまうので、ご注意ください。)
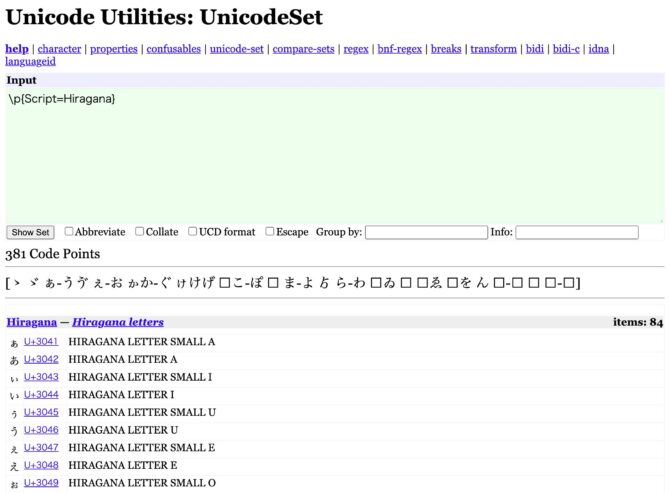
Unicodeのコードポイント Range: 3040–309Fに含まれるひらがなをはじめとして、様々な文字とマッチできることが分かります。
> \p{Script=Hiragana}でマッチする文字 | Unicode Utilities: UnicodeSet
サロゲートペアを使用する文字にもマッチ可能
漢字にマッチさせる\p{Script=Han}ですが、なんとCJK Extension Bをはじめとしたサロゲートペアを使用する漢字たちまで判定対象になります!
先述の実行結果を見ても、「魚へんに花(ほっけ)」(符号U+29E3D= 10 | 10011110 | 00111101)が、うまくマッチできています。
かつて、よく使われていた「一-龥ぁ-んァ-ヶ」では、サロゲートペアを使用する漢字たちを判定に含めることができず、かなりの苦戦を強いられていました。
現代では\p{Script=Han}の一発で判定対象に含まれるようになりました。
時代の進化を感じますね!
なぜ万事を解決するコードではないのか
紹介したコードを使えば「ある文字列に日本語が含まれるか」は、かなりそれっぽいレベルの判定が可能でしょう。
しかしながら、いくつか注意点があります。
注意点1:マッチする範囲の決めは必要
まず大前提として「マッチする範囲はどこまでか」は、あらかじめ取り決める必要があります。/\p{Script=XXX}/uは、何でもよしなに解決してくれる魔法ではありません。注意して利用しないと意図しないマッチが発生してしまいます。
例えば、約物・記号は注意が必要です。hasJapanese関数は、約物・記号を/\p{Script=Common}/uでマッチさせていますが、実はScript=Commonでマッチする範囲は広大です。
「㎏」や「㎝」などの単位記号にもマッチしますし、その他で「〶」や「〠」なども。
「 (U+06DD)」などの他言語の記号ともマッチしますし、果ては「😀」にもマッチします。
Script=Commonは特定の文字体系に限定されず、広く利用される数字、句読点、記号、制御文字…などをまとめたモノだからです。
例えば「。(句点)」は、ひらがなでもカタカナでも使われますよね。こういった文字がScript=Commonに含まれます。
> \p{Script=Common}でマッチする範囲 | Unicode Utilities: UnicodeSet
「日本語に関わる約物(句読点など)にはマッチさせたい。他言語や絵文字とはマッチさせたくない」のであれば、/\p{Script=Common}/uから指定方法を変える必要があります。
代替案として、\p{Script=Common}でマッチする範囲のうち、「CJK Symbols And Punctuation」で検索して、必要となるUnicodeの符号のみを狙い撃ちして指定する方法があります。if (/\p{Script=Common}/u.test(target)) return true;の代わりに、if (/[\u3000-\u3006]/.test(target)) return true;のようなコードを地道に追加していくことになります。
/**
* 引数に日本語が含まれるかを判定する
*
* @param {string} target
* @return {boolean}
*/
const hasJapanese = (target) => {
// ひらがな
if (/\p{Script=Hiragana}/u.test(target)) return true;
// カタカナ
if (/\p{Script=Katakana}/u.test(target)) return true;
// 漢字
if (/\p{Script=Han}/u.test(target)) return true;
// 約物・記号など
// if (/\p{Script=Common}/u.test(target)) return true;
// https://www.unicode.org/charts/PDF/U3000.pdf
// CJK symbols and punctuation
if (/[\u3000-\u3006]/.test(target)) return true;
// CJK angle brackets
if (/[\u3008-\u300B]/.test(target)) return true;
// CJK corner brackets
if (/[\u300C-\u300F]/.test(target)) return true;
// CJK brackets
if (/[\u3010-\u301B]/.test(target)) return true;
// CJK symbol
if (/[\u3012-\u3037]/.test(target)) return true;
// CJK punctuation
if (/[\u301C-\u303D]/.test(target)) return true;
// Kana repeat marks
if (/[\u3031-\u3035]/.test(target)) return true;
// Special CJK indicators
if (/[\u303E-\u303F]/.test(target)) return true;
// その他で、必要な符号があれば随時追加していく
return false;
};注意点2:Unicodeの改定
もう一つの注意点は、Unicodeが改定され続けている点です。
(一応、注意点として挙げますが、コチラはそこまで気にせずで良いと思います。)
身近な例を挙げるなら「㋿」の登場でしょうか。
また、とくに漢字は変化が著しく、2023年にも622字の新たな漢字が追加されています。
> Unicode® Statistics
> Unicode® Version 15.1 Character Counts
Unicodeが改定されて、世の中の端末に浸透していく際に、どうしてもタイムラグが発生します。
今後考えられる例としては、「㋿」に次ぐ新しい元号の記号が登場したときに、最新の端末ではhasJapanese関数で新しい元号の記号を判定できるものの、古い端末では判定できない…なんて事が起こりえるかもしれません。hasJapanese関数の振る舞いが、今後も絶対に変わらないか?と問われると、100%Yesと言えないのが難しいところです。
…とはいえ、上記の例も極端ですし、正直そこまで敏感にならなくて良いと思います。
そもそも、Unicodeの改定はアプリケーション開発者側で対応できる範囲を超えていますし、「Unicodeは改定され続けているんだな」と記憶の片隅に留めておくレベルで良いでしょう。
以上、2つの注意点が「万事を解決するコードではありません」とした理由になります。
まとめ
「万事を解決するコードではありません」と述べたものの、/\p{Script=XXX}/uが非常に強力な機能であることに変わりありません。
とくに、ひらがな・カタカナ・漢字の判定には、十分に利用できるレベルと思います。
今後は「一-龥ぁ-んァ-ヶ」を使うこともなさそうですね。
/\p{Script=XXX}/uを扱えるように整備してくれた方々に感謝しかありません!
感謝の意を込めて、使い倒していく所存です!!
Gaji-Laboでは、その時々のモダンなフロントエンド技術を積極的に採用しています。
技術的にも積極的にチャレンジできる環境が整っていますので、フロントエンドエンジニア職に興味のある方はお気軽にご応募ください!
Gaji-Labo フロントエンドエンジニア向けご案内資料
Gaji-Laboでは、 Next.js 経験が豊富なフロントエンドエンジニアを募集しています
弊社では Next.js の知見で事業作りに貢献したいフロントエンドエンジニアを募集しています。大きな制作会社や事業会社とはひと味もふた味も違う Gaji-Labo を味わいに来ませんか?
Next.js の設計・実装を得意とするフロントエンドエンジニア募集要項
もちろん、一緒にお仕事をしてくださるパートナーさんも随時募集中です。まずはお気軽に声をかけてください。お仕事お問い合わせや採用への応募、共に大歓迎です!